
RAG erklärt: KI-Antworten auf Basis eurer eigenen Daten
Euer Chatbot soll Kundenfragen beantworten, aber bitte mit euren Informationen, nicht mit dem, was das KI-Modell irgendwo im Internet gelernt hat. Genau das ist das Problem, das Retrieval- Augmented Generation löst.
RAG ist 2026 die meistgenutzte Architektur für unternehmenseigene KI-Anwendungen. Nicht weil sie neu wäre (Meta AI hat das Konzept bereits 2020 vorgestellt), sondern weil sie das zentrale Problem von Large Language Models adressiert: Halluzinationen.
Wie RAG funktioniert: Die drei Schritte
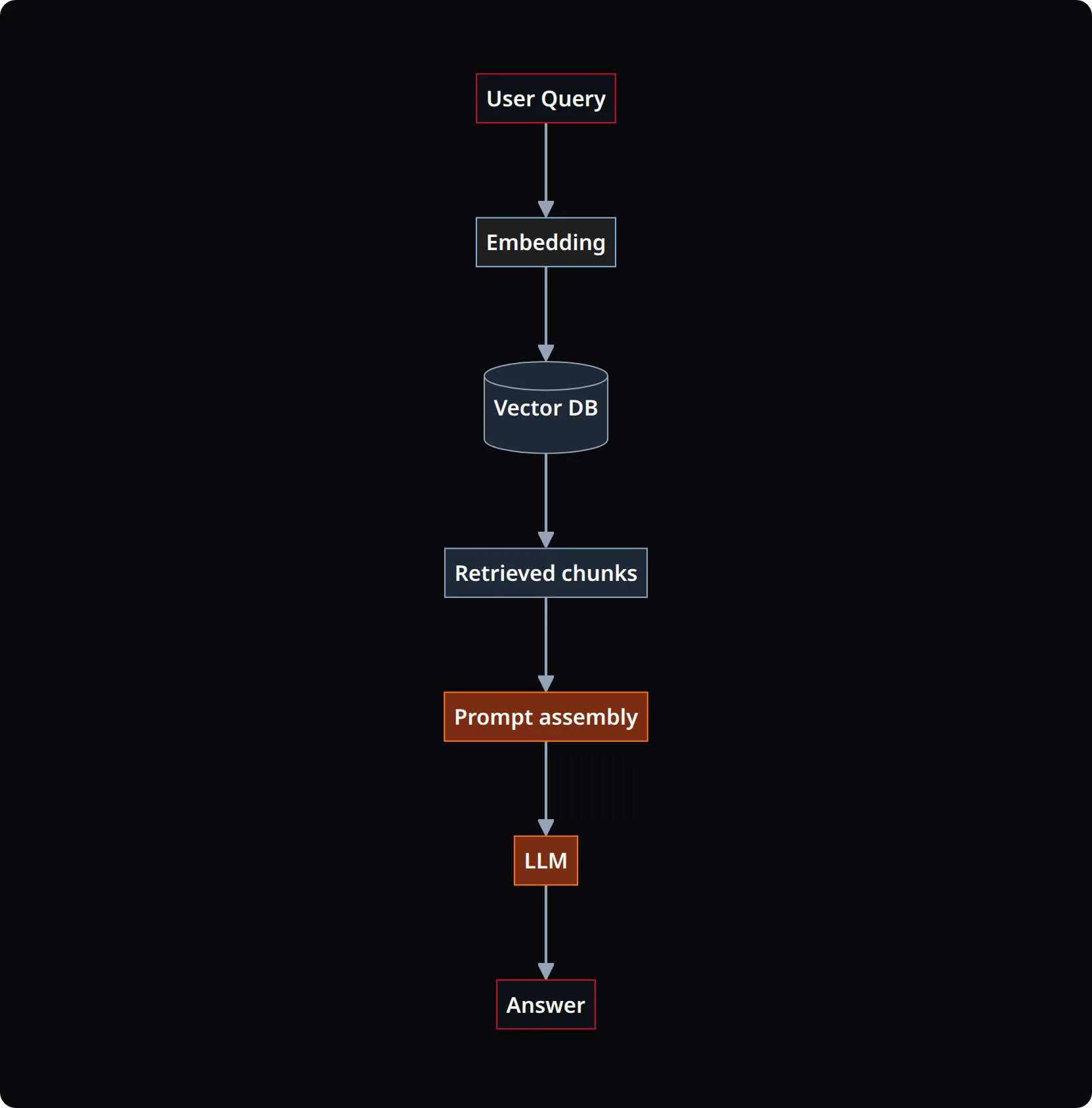
RAG kombiniert zwei KI-Disziplinen: Information Retrieval (Suche) und Text Generation (Erzeugung). Der Ablauf:
Schritt 1, Indexierung: Eure Inhalte (Website-Texte, PDFs, FAQs, Produktdaten) werden in Textbausteine zerlegt und als Vektoren in einer Vektordatenbank gespeichert. Jeder Vektor repräsentiert die Bedeutung eines Textabschnitts.
Schritt 2, Retrieval (Abruf): Wenn ein Nutzer eine Frage stellt, wird diese ebenfalls in einen Vektor umgewandelt. Die Vektordatenbank findet die inhaltlich relevantesten Textabschnitte, typischerweise die 3-10 passendsten Treffer.
Schritt 3, Generation (Erzeugung): Die gefundenen Textabschnitte werden zusammen mit der Nutzerfrage an ein LLM wie Claude oder GPT übergeben. Das Modell generiert eine Antwort, die auf euren eigenen Daten basiert, nicht auf seinem allgemeinen Training.
Das Ergebnis: präzise, quellenbasierte Antworten statt generischer KI-Texte.
Warum RAG besser ist als reines Prompting
Ein LLM ohne RAG hat drei strukturelle Probleme:
Halluzinationen: Das Modell erfindet plausibel klingende Antworten, wenn es die richtige nicht kennt. Mit RAG bekommt es die richtigen Informationen als Kontext, und die Halluzinationsrate sinkt messbar.
Veraltetes Wissen: LLMs haben einen Wissens-Cutoff. Eure Produktpreise von letzter Woche kennen sie nicht. RAG greift auf eure aktuelle Datenbasis zu.
Keine Quellenangaben: Ein LLM kann nicht sagen, woher es seine Antwort hat. Ein RAG-System kann die Quellen mitliefern, sodass jede Antwort nachprüfbar wird.
Ein weiterer Vorteil: RAG ist deutlich günstiger als Fine-Tuning. Statt das Modell mit euren Daten neu zu trainieren, gebt ihr ihm die relevanten Informationen zur Laufzeit.
RAG vs. Fine-Tuning: Wann was?
RAG eignet sich, wenn: - Eure Daten sich regelmäßig ändern (Produkte, Preise, News) - Quellenangaben wichtig sind (Compliance, Kundensupport) - Ihr schnell starten wollt (Wochen statt Monate) - Budget begrenzt ist (kein GPU-Cluster für Training nötig)
Fine-Tuning eignet sich, wenn: - Das Modell einen bestimmten Stil oder Tonfall lernen soll - Die Aufgabe hochspezialisiert ist (z.B. medizinische Texte) - Performance bei wiederkehrenden Aufgaben maximiert werden soll
In der Praxis kombinieren viele Unternehmen beides: Ein fine-getuntes Modell mit RAG-Zugang zu aktuellen Daten. arocom berät zur richtigen Strategie basierend auf eurem konkreten Anwendungsfall.
RAG in der Praxis: Drei Anwendungsfälle
Intelligente Website-Suche: Nutzer stellen Fragen in natürlicher Sprache. Das RAG-System durchsucht eure Inhalte semantisch und liefert eine zusammengefasste Antwort mit Links zu den Quellseiten. Wir bei arocom setzen das für Drupal-Plattformen um, eure Inhalte werden zur Wissensbasis.
KI-gestützter Kundensupport: Ein Chatbot, der aus euren FAQs, Handbüchern und Support-Dokumenten antwortet. Jede Antwort enthält die Quelle, sodass Support-Mitarbeiter und Kunden die Information verifizieren können.
Interner Wissens-Assistent: Mitarbeiter fragen das System zu Prozessen, Richtlinien oder Produktdetails. RAG durchsucht euer Intranet, Wiki und Dokumentenarchiv und liefert kontextbezogene Antworten.
Ein empfehlenswertes Einführungsvideo von IBM Technology erklärt die Architektur visuell in 7 Minuten:

What is Retrieval-Augmented Generation (RAG)?: IBM Technology
RAG-Techstack: Was ihr braucht
Ein RAG-System besteht aus vier Komponenten:
1. Embedding-Modell: Wandelt Text in Vektoren um. Optionen: OpenAI Ada, Cohere Embed, Open-Source-Modelle wie BGE oder E5.
2. Vektordatenbank: Speichert und durchsucht die Vektoren. Für Drupal-Projekte empfiehlt arocom pgvector (in PostgreSQL integriert) als Einstieg. Mehr dazu: Vektordatenbanken erklärt.
3. LLM: Generiert die Antwort. Claude, GPT-4o oder Open-Source-Modelle wie Llama.
4. Orchestrierung: Verbindet die Komponenten. Frameworks wie LangChain oder LlamaIndex vereinfachen den Aufbau. Für AI Agents kommt zunehmend MCP als Standardprotokoll zum Einsatz.
RAG für eure Drupal-Plattform?
Ob intelligente Suche, Chatbot oder Wissens-Assistent: arocom plant und implementiert RAG-Architekturen. Schreibt uns für ein unverbindliches Gespräch.
RAG-Beratung anfragenWas ist RAG (Retrieval-Augmented Generation)?
RAG ist eine KI-Architektur, die Large Language Models mit externen Wissensquellen verbindet. Statt nur auf Trainingsdaten zu vertrauen, durchsucht ein RAG-System eure eigenen Dokumente und generiert Antworten auf Basis dieser Quellen. Das reduziert Halluzinationen und macht Antworten nachprüfbar.
Wann brauche ich RAG?
Immer wenn ein KI-System mit euren eigenen, aktuellen Daten arbeiten soll, etwa für Website-Suche, Kundensupport-Chatbots oder interne Wissens-Assistenten. Wenn generische KI-Antworten ausreichen, ist RAG nicht nötig.
Was ist der Unterschied zwischen RAG und Fine-Tuning?
RAG gibt dem Modell relevante Informationen zur Laufzeit als Kontext. Fine-Tuning trainiert das Modell mit euren Daten neu. RAG ist schneller, günstiger und hält Daten aktuell. Fine-Tuning eignet sich für spezialisierte Aufgaben und Stilanpassungen.
Welche Datenquellen kann RAG nutzen?
Praktisch alle textbasierten Quellen: Website-Inhalte, PDFs, Word-Dokumente, FAQs, Datenbanken, Wikis, Support-Tickets. Die Inhalte werden einmalig indexiert und stehen danach für Abfragen zur Verfügung.
Wie teuer ist eine RAG-Implementierung?
Die laufenden Kosten bestehen aus API-Kosten für das LLM (wenige Cent pro Abfrage) und Hosting der Vektordatenbank. Die Hauptinvestition liegt in der initialen Konzeption und Integration. arocom berät zur realistischen Gesamtkosteneinschätzung.
Kann RAG Halluzinationen komplett verhindern?
Nein, aber deutlich reduzieren. RAG gibt dem Modell die richtigen Informationen als Kontext. Wenn die Antwort nicht in den Quellen steht, kann das Modell trotzdem spekulieren. Deshalb gehört zu jeder RAG-Implementierung eine Qualitätssicherungs-Schicht.
Wie steht es um KI & Automatisierung auf eurer Website? Der Zukunfts-Check zeigt in 2–4 Wochen, wo die größten Hebel liegen.
Mit dem Wissen weiterarbeiten
Weiterlesen
Kopiert diesen Prompt und fügt ihn in ChatGPT, Claude oder eine andere KI ein — ihr bekommt einen persönlichen Lernplan zu „RAG erklärt: Retrieval-Augmented Generation für Unternehmen“.
Du bist ein erfahrener Coach für KI & Automatisierung. Ich möchte das Thema "RAG erklärt: Retrieval-Augmented Generation...CMS-Vergleich 2025
Drupal vs. WordPress vs. TYPO3: Ein objektiver Vergleich für Enterprise-Projekte.
War dieser Artikel hilfreich?